
PowerShell - Remove special characters from a string using Regular Expression (Regex)
 Some more string manipulations! Today I’d like to remove the special characters and only keep alphanumeric characters using Regular Expression (Regex).
Some more string manipulations! Today I’d like to remove the special characters and only keep alphanumeric characters using Regular Expression (Regex).
You might be interested to check a previous article where I showed how to remove diacritics (accents) from some strings, see here: https://lazywinadmin.github.io/2015/05/powershell-remove-diacritics-accents.html
My goal is to be able to keep only any characters considered as letters and any numbers.
If you are familiar with Regex, you could do something simple as using the metacharacter \w or [a-z] type of things. It’s great when you only work with english language but does not work when you have accents or diacritics with Latin languages for example.
Preview of the final solution:
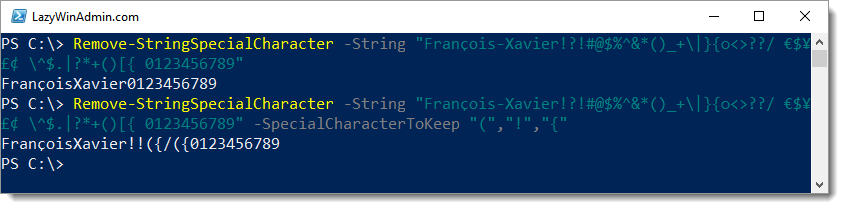
Regex approachesPermalink
Here is a couple of examples using different meta-characters and Unicode techniques.
I stored the string in a variable $String to make it easy to read.
$String = "François-Xavier!?!#@$%^&*()_+\|}{○<>??/ €$¥£¢ \^$.|?*+()[{ 0123456789"
\W Meta-characterPermalink
# Regular Expression - Using the \W (opposite of \w)
$String -replace '[\W]', ''
The \w metacharacter is used to find a word character. A word character is a character from a-z, A-Z, 0-9, including the _ (underscore) character. Here we use \W which remove everything that is not a word character. This works pretty well but we get an extra underscore character _. The diacritics on the c is conserved.

[^a-zA-Z0-9] RangesPermalink
# Regular Expression - Using characters from a-z, A-Z, 0-9
$String -replace '[^a-zA-Z0-9]', ''
Note: The ^ character allows us to get the opposite (inverse) of the regex pattern defined.

This is working well, but the diacritics are removed. (Missing C of “François”)
ASCII RangesPermalink
# Regular Expression - Using ASCII
# See http://www.asciitable.com/
$String -replace '[^\x30-\x39\x41-\x5A\x61-\x7A]+', ''

Same here, we are using specific ranges of ASCII Characters. The diacritics are removed. (Missing C of “François”)
UNICODE Specific Code PointPermalink
# Regular Expression - Unicode - Matching Specific Code Points
# See http://unicode-table.com/en/
$String -replace '[^\u0030-\u0039\u0041-\u005A\u0061-\u007A]+', ''

Same here again, we are using specific ranges of Unicode Code Point Characters. The diacritics are removed. (Missing C of “François”)
UNICODE Categories (This is what I use in my final function)Permalink
# Regular Expression - Unicode - Unicode Categories
$String -replace '[^\p{L}\p{Nd}]', ''
Each Unicode character belongs to a certain category. You can match a single character belonging to the “letter” category with\p{L}. Same for Numbers, you can use \p{Nd} for Decimals.

Other cool Example such as \p{N} for any type of numbers, \p{Nl} for a number that looks like a letter, such as a Roman numeral and finally \p{No} for a superscript or subscript digit, or a number that is not a digit 0-9.
This is the method I use in the final function.
Keep some specific charactersPermalink
Now that I have the main code working. I want to include some Exclusion. This can easily be done with the slash character, example:
# Regular Expression - Unicode - Unicode Categories
# Exceptions: We want to keep the following characters: ( } _
$String -replace '[^\p{L}\p{Nd}/(/}/_]', ''

Final FunctionPermalink
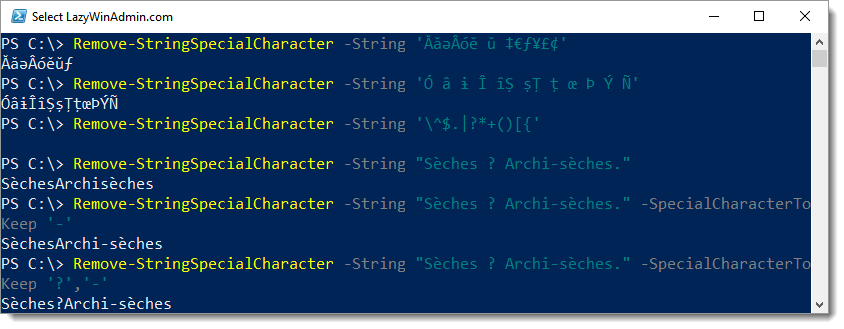
Sample of the code as of 2018/10/02
function Remove-StringSpecialCharacter
{
<#
.SYNOPSIS
This function will remove the special character from a string.
.DESCRIPTION
This function will remove the special character from a string.
I'm using Unicode Regular Expressions with the following categories
\p{L} : any kind of letter from any language.
\p{Nd} : a digit zero through nine in any script except ideographic
http://www.regular-expressions.info/unicode.html
http://unicode.org/reports/tr18/
.PARAMETER String
Specifies the String on which the special character will be removed
.SpecialCharacterToKeep
Specifies the special character to keep in the output
.EXAMPLE
PS C:\> Remove-StringSpecialCharacter -String "^&*@wow*(&(*&@"
wow
.EXAMPLE
PS C:\> Remove-StringSpecialCharacter -String "wow#@!`~)(\|?/}{-_=+*"
wow
.EXAMPLE
PS C:\> Remove-StringSpecialCharacter -String "wow#@!`~)(\|?/}{-_=+*" -SpecialCharacterToKeep "*","_","-"
wow-_*
.NOTES
Francois-Xavier Cat
@lazywinadmin
www.lazywinadmin.com
github.com/lazywinadmin
#>
[CmdletBinding()]
param
(
[Parameter(ValueFromPipeline)]
[ValidateNotNullOrEmpty()]
[Alias('Text')]
[System.String[]]$String,
[Alias("Keep")]
#[ValidateNotNullOrEmpty()]
[String[]]$SpecialCharacterToKeep
)
PROCESS
{
IF ($PSBoundParameters["SpecialCharacterToKeep"])
{
$Regex = "[^\p{L}\p{Nd}"
Foreach ($Character in $SpecialCharacterToKeep)
{
IF ($Character -eq "-"){
$Regex +="-"
} else {
$Regex += [Regex]::Escape($Character)
}
#$Regex += "/$character"
}
$Regex += "]+"
} #IF($PSBoundParameters["SpecialCharacterToKeep"])
ELSE { $Regex = "[^\p{L}\p{Nd}]+" }
FOREACH ($Str in $string)
{
Write-Verbose -Message "Original String: $Str"
$Str -replace $regex, ""
}
} #PROCESS
}
Leave a comment